数据类型
原创...大约 7 分钟
数据类型
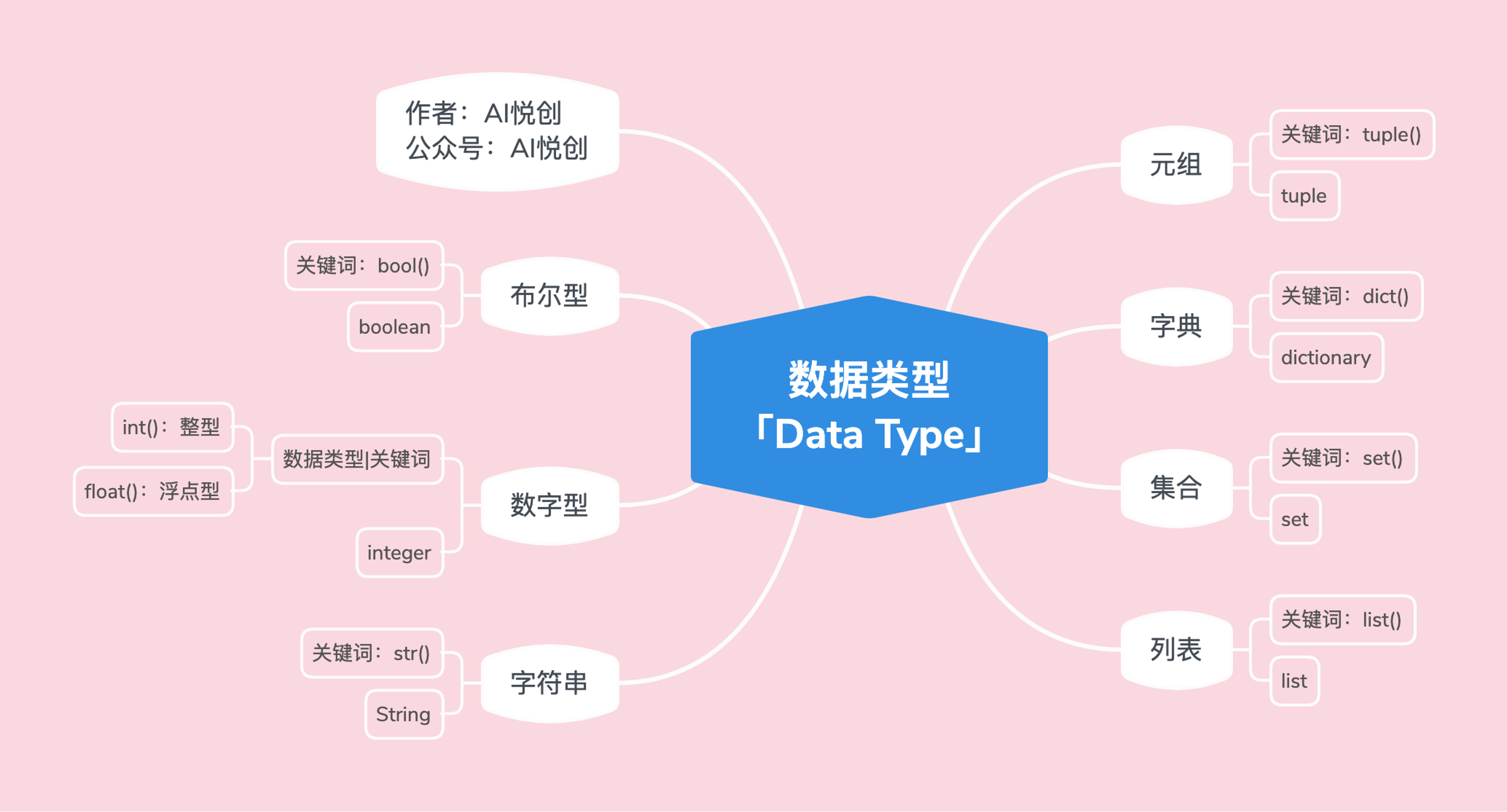
1. 数字型 [int, float]
1.1 代码示例
整型
int_num = 1 t = type(int_num) # check data type print(int_num) print("int num type is:>>>", t) print("直接检测数据类型,并输出:>>>", t) # output 1 int num type is:>>> <class 'int'> 直接检测数据类型,并输出:>>> <class 'int'>浮点数
float_num = 1.5 t = type(float_num) # check data type print(float_num) print("float num type is:>>>", t) print("直接检测数据类型,并输出:>>>", t) # output 1.5 float num type is:>>> <class 'float'> 直接检测数据类型,并输出:>>> <class 'float'>
2. 字符串 [str]
2.1 代码示例
string = "Hello Alexa"
t = type(string)
print(string)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
Hello Alexa
string type is:>>> <class 'str'>
直接检测数据类型,并输出:>>> <class 'str'>
2.2 字符串的三大特性
- 有序性
- 从左到右,下标从0开始
- 从右到左,下标从-1开始
- 引号里面出现的都算一个下标
- 不可变性
- 字符串被创建出来之后就不能改变
- 注意⚠️:我们说的不可变,是在代码运行的过程当中,不能对字符串修改,添加,删除
- 任意字符
- 键盘上可以输入的字符,都可以是字符串的元素
- 字符放到字符串中,都将成为字符串的类型,也就是里面的每一个元素都可以被称为「子字符」
3. 列表 [list]
3.1 代码示例
lst = ["Hello Alexa", 1, 1.1, ("a", "b", 1), ["x", 2], True, False]
t = type(lst)
print(lst)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
['Hello Alexa', 1, 1.1, ('a', 'b', 1), ['x', 2], True, False]
string type is:>>> <class 'list'>
直接检测数据类型,并输出:>>> <class 'list'>
3.2 列表的三大特性
- 有序性
- 从左到右,下标从0开始
- 从右到左,下标从-1开始
- 列表里面每个元素算一个
- 比如:
lst = [“alexa”, 12] - 上面lst有两个元素,下标分别是:
“alexa”, 从左到右0,从右到左-112, 从左到右1,从右到左-1
- 比如:
- 可变性:在程序运行的过程当中,列表可以「添加,改变,删除」
- 任意数据类型:python拥有的所有数据类型都可以作为元素之一
Python所拥有的所有数据类型「仅包含基础数据类型」
4. 元组 [tuple]
4.1 代码示例
tup = ("Hello Alexa", 1, 1.1, ("a", "b", 1), ["x", 2], True, False)
t = type(tup)
print(tup)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
('Hello Alexa', 1, 1.1, ('a', 'b', 1), ['x', 2], True, False)
string type is:>>> <class 'tuple'>
直接检测数据类型,并输出:>>> <class 'tuple'>
4.2 元组的三大特性
- 有序性
- 从左到右,下标从0开始
- 从右到左,下标从-1开始
- 元组里面每个元素算一个
- 比如:
tup = (“alexa”, 12) - 上面tup有两个元素,下标分别是:
“alexa”, 从左到右0,从右到左-112, 从左到右1,从右到左-1
- 比如:
- 不可变性:在程序运行的过程当中,元组不可以「添加,改变,删除」
- 任意数据类型:python拥有的所有数据类型都可以作为元素之一
4.3 元组VS列表
为什么🧐有列表后,还需要元组
列表和元组到底用哪一个呢?
- 如果存储的数据或数量是可变的,比如社交平台上的一个日志功能,是统计一个用户在一周之内看了哪些用户的帖子——那么则用列表更合适。
- 如果存储的数据和数量不变,比如你有一个系统(软件),需要返回的是一个地点的经纬度,然后直接传给用户查看——那么肯定选用元组更合适。
假设
假设1:现在有一个仓库,你要向仓库添加物品。仓库很大,现有的物品也很多,你不知道还有没有位置可以存放。此时我们是不是需要聘请一个仓库管理员,这样我们就可以直接问仓库管理员:里面还有哪个位置(是否有位置?)仓库管理员会告诉你,并且你可以直接把你的物品,添加进去。
问题来了,仓库管理员为什么知道仓库是否有位置?——因为仓库管理员会一直跟踪这个仓库的状态;
假设2:现在有一个原子弹的仓库,仓库创建之后,只能存放一个原子弹。那么,我们需要设立一个专门的人员跟踪:原子弹仓库的状态吗?——不需要,此时在聘请一个就显得浪费了。(不然,领导没油水了~hhhhh)
Why?
- 用户日志📔,是不是会一直变动(记录📝看了哪些帖子),我们是不是需要有一个类似仓库管理员的“人”,来跟踪并且知道:是否有位置(是否有空间/内存),还需要知道在哪里添加。——列表更合适,因为列表可变。「可变意味着:添加、删除、修改」
- 元组为什么不合适?——因为,你每当需要添加数据的时候,就得重新创建一个新的元组。(就类似于:你创建原子弹的仓库,肯定是刚刚好可以存放一个,那么你想存放两个的时候,只能重新再创建一个仓库。)
- 经纬度会改变吗?显然是不会的,那么就不需要一个多余的“人”去跟踪状态。——用列表可以吗?可以!但是没必要。「因为我们不需要仓库管理员」用列表有点浪费资源了。元组的功能刚刚好够用。
- 我们讲究:不浪费,合适就好。
- 用户日志📔,是不是会一直变动(记录📝看了哪些帖子),我们是不是需要有一个类似仓库管理员的“人”,来跟踪并且知道:是否有位置(是否有空间/内存),还需要知道在哪里添加。——列表更合适,因为列表可变。「可变意味着:添加、删除、修改」
5. 字典 [dict]
5.1 代码示例
d = {"name": "alexa", "age": 18, 1: "int", 1.1: 1, "tup": (1, 2, 3)}
t = type(d)
print(d)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
{'name': 'alexa', 'age': 18, 1: 'int', 1.1: 1, 'tup': (1, 2, 3)}
string type is:>>> <class 'dict'>
直接检测数据类型,并输出:>>> <class 'dict'>
5.2 字典的特性
- 无序性 「python 3.6+ 之后右序」
- 先以无序理解即可
- 有些前期基本用不到
- 字典的组成:是由一系列的 key 和 value 组成
d = {"key1": "value1", "key2": "value2"} - Key:
- 不可变的数据类型才可以当做数据的 key
- 比如:字符串,数字,布尔,元组
- value:任意数据类型,python 所拥有的所有数据类型
- 可变性:可以添加,删改 key 对应的 value
6. 集合 [set]
6.1 代码示例
set1 = {1, 2, "hello", 1.1, (1, 2, 3), False}
t = type(set1)
print(set1)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
{False, 1, 2, 1.1, (1, 2, 3), 'hello'}
string type is:>>> <class 'set'>
直接检测数据类型,并输出:>>> <class 'set'>
6.2 集合的特性
无序性:集合是没有顺序的,也就是没有下标
set1 = {1, 2, "hello", 1.1, (1, 2, 3), False} print(set1) # output {False, 1, 2, 1.1, (1, 2, 3), 'hello'}运行之后顺序可能和输入的顺序不一样
注意
如果你运行集合很多次,或者其中某一次,集合顺序没有改变,我们也不能说集合是有序的。
Why?你掷骰子,500次都是 6 点,你能说掷骰子是确定性事件吗?——显然是不行的🙅。
确定性:
- 集合的每一个值都是确定的,也就是「需要不可变的数据类型」
- 比如:布尔型,数字,元组,字符串
- 举个例子:为什么列表不行 — 列表可变,具有不确定性
可变测试
set1 = {1, 2, "hello", 1.1, (1, 2, 3), False, [1, 2]}
t = type(set1)
print(set1)
print("string type is:>>>", t)
print("直接检测数据类型,并输出:>>>", t)
# output
Traceback (most recent call last):
File "/Users/gaxa/Coder/Pythonfile/data_type.py", line 1, in <module>
set1 = {1, 2, "hello", 1.1, (1, 2, 3), False, [1, 2]}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: unhashable type: 'list'
- 互异性:出现重复的不会报错,会自动去掉重复的!!会自动去重
set2 = {1, 1, 1, 2, 2, 3}
print(set2)
# output
{1, 2, 3}
- 可变性:可以对集合添加,删除数据,但是不能修改输出 「注意:删除是无法指定下标的删除元素」
7. 布尔型 [bool]
7.1 代码示例
condition = True # False
print(condition)
print(type(condition))
# output
True
<class 'bool'>
你认为这篇文章怎么样?
 0
0 0
0 0
0 0
0 0
0 0
0